數據科學學院師生18篇論文被NeurIPS 2022接收
近日,香港中文大學(深圳)數據科學學院師生共18篇論文被機器學習和計算神經科學領域的頂級國際會議神經信息處理系統大會?2022(Conference on Neural Information Processing Systems,簡稱NeurIPS或NIPS)接收。論文來自數據科學學院12位教授(樊繼聰、李海洲、李肖、羅智泉、Andre Milzarek、孫若愚、王本友、吳保元、謝李巖、嚴明、查宏遠、張瑞茂)、1位博士后(郭丹丹)和1位博士生(張雨舜)。NeurIPS 2022共收到10411篇論文投稿,錄取率為25.6%。本文將為您簡要介紹我校被接收的18篇論文。
NeurlPS簡介
神經信息處理系統大會(簡稱NeurIPS或NIPS)是機器學習和計算神經科學領域的頂尖國際會議。在中國計算機學會的國際學術會議排名中,NeurIPS是人工智能領域的A類學術會議。大會討論的內容包含深度學習、計算機視覺、大規模機器學習、學習理論、優化、稀疏理論等眾多細分領域。該會議固定在每年的12月舉行, 由NIPS基金會主辦,今年是該會議舉辦的第36屆,將于11月28日至12月9日舉行,為期兩周。本屆會議采用混合模式,第一周將在美國新奧爾良會議中心舉行線下會議,第二周為線上會議。
來源:NeurIPS官網、百度百科
18篇論文的詳細介紹如下? ?:
(文章按學院教授和學生姓名首字母排序)
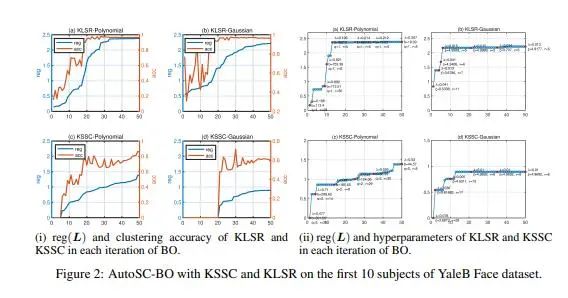
1.?A Simple Approach to Automated Spectral Clustering
作者:
Jicong Fan, Zhao Zhang, Yiheng Tu, Mingbo Zhao, Haijun Zhang
簡介:
傳統的自動機器學習方法都是為有監督學習任務提出的,本論文研究自動無監督機器學習,提出了一種自動譜聚類方法, 能夠自動選擇構造鄰接矩陣的模型、調節超參數,并能擴展于大規模聚類問題。本論文證明了所提指標relative-eigen-gap的有效性以及(核)最小二乘回歸在構造鄰接矩陣時的有效性。
鏈接:
https://arxiv.org/abs/2107.12183v4
?
2.?Perturbation Learning Based Anomaly Detection
作者:
Jinyu Cai,?Jicong Fan
簡介:
論文提出了一種基于擾動學習異常檢測方法。該方法利用訓練數據(正常)學習一個擾動器給正常數據添加擾動以生成異常數據,同時學習一個判別器能夠區別正常數據和生成的異常數據。該方法不需要對正常數據的分布進行任何假設,在多個基準數據集上取得了最好的效果。

鏈接:
https://arxiv.org/abs/2206.02704
?
3.?Learning to Re-weight Examples with Optimal Transport for Imbalanced Classification
作者:
Dandan Guo, Zhuo Li, Meixi Zheng, He Zhao, Mingyuan Zhou,?Hongyuan Zha
簡介:
深度學習模型在很多分類任務上取得了極大的成功,這種成功與高質量、平衡的訓練數據集是密不可分的。然而現實應用中經常存在不平衡的訓練數據集,對深度學習模型的訓練造成極大挑戰。

本文針對不平衡分類任務,提出了一種基于最優傳輸(OT)的自動重加權方法。該方法將不平衡訓練集表示為關于訓練樣本的可學習分布,每個訓練樣本都有對應的采樣概率。類似地,我們將另一個平衡的元集視為平衡分布。通過最小化兩個分布之間的OT距離,將權重向量的學習表示為一個分布近似問題。我們提出的重加權方法繞過了現有方法采用的分類損失,使用OT作為損失函數來學習權重,在每次迭代中消除了權重學習對相關分類器的依賴。這種方法不同于大多數現有的重加權方法,可能為未來的工作提供新的思路。在各種圖像、文本和點云的不平衡數據集上的實驗結果驗證了該方法的有效性和靈活性。

鏈接:
https://arxiv.org/abs/2208.02951v1
?
4.?Adaptive Distribution Calibration for Few-Shot Learning with Hierarchical Optimal Transport
作者:
Dandan Guo, Long Tian, He Zhao, Mingyuan Zhou,?Hongyuan Zha
簡介:
機器學習中小樣本分類的目的是學習一個分類器,使其在測試階段識別訓練階段未見過的類,此時測試階段的有標簽樣本數量較少,模型很容易發生過擬合。解決該問題的一個最新方案是轉移基類的統計信息來校準這些新的小樣本類的分布,其中如何決定從基類到新類的轉移權值是關鍵。目前,該問題尚未得到深入研究。為此,我們提出了一種新的層次最優傳輸(H-OT)算法,來學習新樣本和基類之間的自適應權重矩陣。通過最小化新樣本與基類之間的High-level OT距離,我們可以將學習到的傳輸概率視為自適應傳輸矩陣。
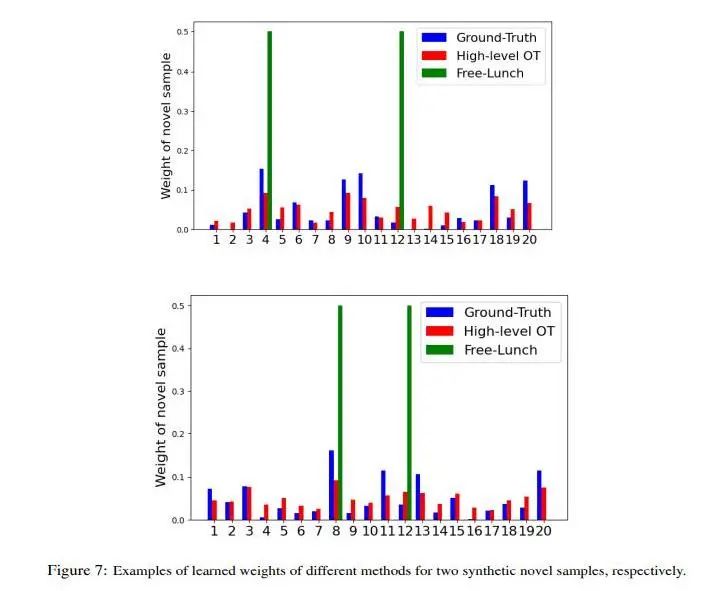
此外,我們又引入了Low-level OT,此時考慮了基類中所有數據樣本的權重,并用Low-level OT中學到的距離來定義High-level OT的傳輸代價。在標準數據集上的實驗結果表明,我們提出的即插即用模型優于競爭方法,并具有良好的跨域泛化能力,表明了學習到的自適應權值的有效性。
鏈接:
https://arxiv.org/abs/2107.12183v4
?
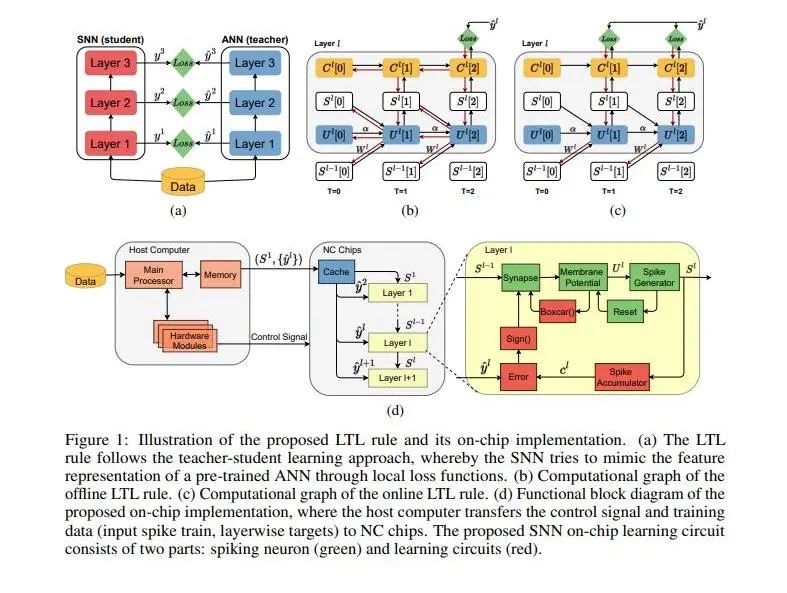
5.?Training Spiking Neural Networks with Local Tandem Learning
作者:
Qu Yang, Jibin Wu, Malu Zhang, Yansong Chua, Xinchao Wang,?Haizhou Li
簡介:
本文研究一個新的脈沖神經網絡學習算法。此算法基于遷移學習的理論,將傳統神經網絡的學習結果遷移到脈沖神經網絡中,充分地利用了傳統神經網絡的強大學習能力和脈沖神經網絡的高效計算,完成多種模式識別任務。本研究為類腦計算的低功耗實現提出了新的解決方案。
?
6.?A Unified Convergence Theorem for Stochastic Optimization Methods
作者:
Xiao Li, Andre Milzarek
簡介:
本論文針對一般的隨機優化方法提出了一個統一的收斂性定理的證明框架,其中收斂性主要指迭代最終步的梯度范數依期望收斂或者幾乎必然收斂到0。本項工作的意義主要在于兩點:


(1) 不同于已有的復雜度類型的結果,我們討論的方法與實際應用更為貼合,例如迭代步長的選取不依賴于迭代總步數,探討的收斂性針對最后一迭代的梯度而非所有迭代在某種平均下的梯度或者所有迭代的梯度的最小值,這一點尤其重要,因為隨機算法在迭代過程中并不會計算全梯度,并且算法通常會返回最后一次迭代,所以,只有估計最后一次迭代的梯度范數的表現才是最有意義的。
(2) 當下已有的一些類似的收斂性結果通常只針對某類特殊的算法,我們對于一般的隨機優化算法提出了通用的證明框架,使用者只需要驗證算法是否滿足若干典型條件即可。我們運用這一收斂框架在更弱的假設下重現了stochastic gradient method (SGD) 和random reshuffling (RR) 的收斂性證明,并且對更復雜的stochastic proximal gradient method (prox-SGD)?和stochastic model-based methods (SMM) 兩種算法也得到了依期望收斂和幾乎必然收斂的結果。

該文章中所提出的統一收斂框架有望被廣泛應用于其他隨機算法,例如Momentum SGD和STORM等。
鏈接:
https://arxiv.org/abs/2206.03907
?
7.?DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data
作者:
Tiantian Fang,?Ruoyu Sun, Alex Schwing
簡介:
生成對抗網絡(GAN)在學習從給定數據集指定的分布中進行采樣方面取得了顯著成功,特別是在數據比較多的情況下。然而,當數據有限時,傳統的GAN表現不佳,而輸出正則化、數據增強、使用預訓練模型和修剪等策略已被證明可以帶來改進。值得注意的是,這些策略的適用性通常受限于特定設置,例如需要預訓練GAN、訓練時間足夠多或使用剪枝。我們提出了一個判別器梯度間隙正則化 GAN(DigGAN)公式,它可以添加到任何現有的GAN中。DigGAN通過鼓勵縮小鑒別器預測的梯度范數之間的差距來增強現有的GAN。我們觀察到這個公式是為了避免GAN損失領域中的不良吸引子,并且我們發現DigGAN在可用數據有限時顯著改善了GAN訓練的結果。
?
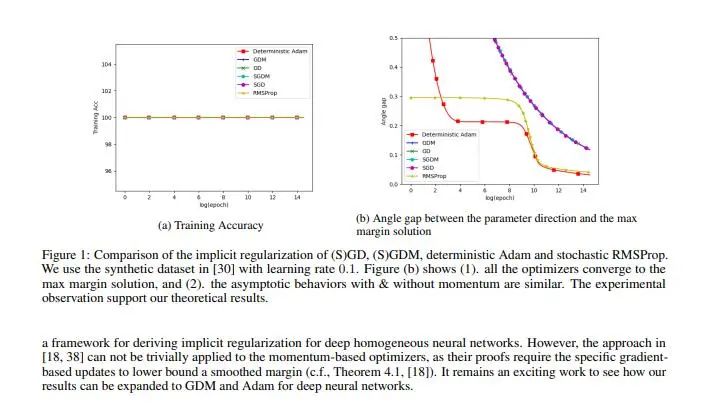
8.?Does Momentum Change the Implicit Regularization on Separable Data?
作者:
Bohan Wang, Qi Meng, Huishuai Zhang,?Ruoyu Sun,?Wei Chen, Zhi-Ming Ma, Tie-Yan Liu
簡介:
動量加速技術在許多優化算法中被廣泛采用。然而,關于動量如何影響優化算法的泛化性能,目前還沒有理論答案。本文通過分析基于動量優化的隱式正則化來研究這個問題。我們證明,在具有可分離數據和指數尾損失的線性分類問題上,動量梯度下降 (GDM) 收斂到 $L^2$ 最大邊距的解,這與普通梯度下降相同。這意味著具有動量加速的梯度下降仍然會收斂到一個低復雜度的模型,這保證了它們的泛化性。然后,我們分析 GDM 的隨機和自適應變體(即SGDM和確定性Adam),并表明它們也收斂到 $L^2$ 最大邊距的解。從技術上講,為了克服動量分析中誤差累積的困難,我們構造了新的勢函數來分析模型參數和最大邊距解之間的差距。數值實驗支持了我們的理論結果。
鏈接:
https://arxiv.org/abs/2110.03891
?
9.?Stability Analysis and Generalization Bounds of Adversarial Training
作者:
Jiancong Xiao, Yanbo Fan,?Ruoyu Sun, Jue Wang,?Zhi-Quan Luo
簡介:
在對抗機器學習場景下,神經網絡可以很好地擬合訓練集上的對抗樣本,但是無法很好地泛化到測試集上的對抗樣本,這個現象叫做魯棒過擬合(robust overfitting)。這篇文章從一致穩定性(uniform stability)的角度分析這一個現象。然而,由于對抗訓練的損失函數不光滑,現有的基于光滑損失函數的一致穩定性分析無法應用到對抗訓練場景。針對這個問題,我們首先定義近似光滑性并證明對抗損失函數滿足近似光滑性。然后我們構建了針對近似光滑性的一致穩定性框架,在我們的框架下,我們給出了對抗訓練的一致穩定性分析和泛化誤差上下界。
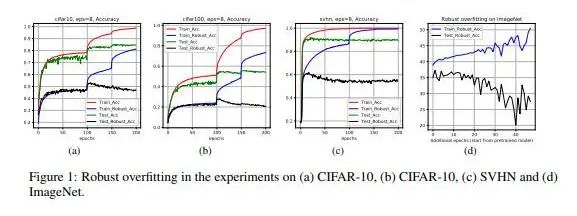
我們從理論上證明了,如果使用攻擊強度為eps的對抗樣本進行對抗訓練當訓練輪數T過大,魯棒測試誤差會以一個O(eps T)與O(eps sqrt(T))之間的速度的上升。我們的理論指出魯棒過擬合可能是由對抗損失函數的近似光滑性導致的。我們在常規數據集(如CIFAR-10,ImageNet)上驗證了我們的理論。另外,基于我們的分析框架下,我們計算了一些常用的的對抗訓練技術(如循環學習率,隨機權重平均等)的泛化誤差上界,并證明了它們能從一定程度上緩解魯棒過擬合。
鏈接:
https://arxiv.org/abs/2210.00960
?
10.?MorphTE: Injecting Morphology in Tensorized Embeddings?
作者:
Guobing Gan, Peng Zhang, Sunzhu Li, Xiuqing Lu,?Benyou Wang
簡介:
在深度學習時代,詞嵌入在處理文本任務時是必不可少的。但是,存儲這些嵌入需要大量空間,這對資源有限的設備上的部署不友好。結合張量積強大的壓縮能力,我們提出了一種帶有形態增強的詞嵌入壓縮方法,詞素(Morphology)增強張量嵌入(MorphTE)。一個詞由一個或多個詞素組成,詞素是具有意義或具有語法功能的最小單位。MorphTE 通過張量積將詞嵌入表示為其語素向量的張量積形式,將先驗的構詞知識注入到詞嵌入的學習中。此外,詞素向量的維數和詞素的數量相比詞向量維度和詞的個數小得多,這大大減少了詞嵌入的參數。我們對機器翻譯和問答等任務進行實驗。在四個不同語言的翻譯數據集上的實驗結果表明,MorphTE 可以將詞嵌入參數壓縮約 20 倍而沒有性能損失,并且明顯優于存在的嵌入壓縮方法。
鏈接:
https://wabyking.github.io/papers/MorphTE-NeurIPS2022.pdf
?
11.?Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation
?
作者:
Zeyu Qin, Yanbo Fan, Yi Liu, Li Shen, Yong Zhang, Jue Wang,?Baoyuan Wu
簡介:
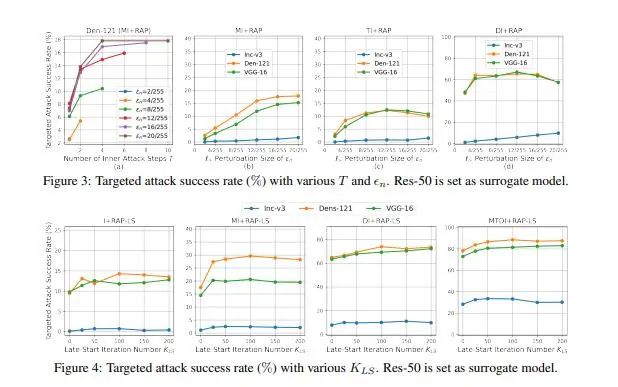
我們已經了解到深度神經網絡 (DNN) 非常容易受到對抗樣本的干擾,對抗樣本通過在原樣本上加入人眼難以察覺的擾動來使模型產生錯誤的預測。同時,對抗樣本的遷移性使得其對模型架構或參數未知的實際模型應用構成嚴重的威脅。因此,在這項工作中,我們著重研究對抗樣本的遷移性。許多現有的工作表明,對抗樣本可能會過度擬合產生其的替代模型,從而限制了針對不同目標模型的遷移攻擊性能。為了減輕對抗樣本對于替代模型的過度擬合,我們提出了一種新的攻擊方法,稱為反向對抗擾動(RAP)。

具體來說,我們提出通過為樣本優化過程的每一步注入最壞情況的擾動(反向對抗擾動)來尋找位于具有局部統一較低損失值區域的對抗樣本,而不是簡單追求單個對抗樣本點具有較低損失。因此,結合RA 產生對抗攻擊的過程可以被表述為一個最小-最大雙層優化問題。通過將RAP加入到產生攻擊樣本的迭代過程中,我們的方法可以找到更穩定的對抗樣本,這些對抗樣本對模型決策邊界的變化不太敏感,從而減輕了對于替代模型的過度擬合。綜合實驗比較表明,RAP可以顯著提高對抗遷移性。
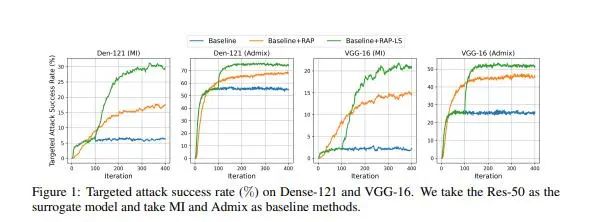
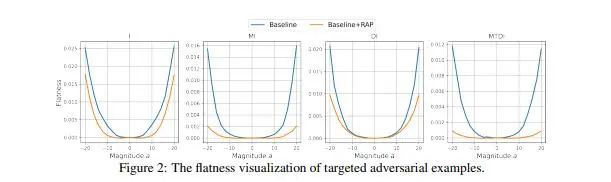
此外,RAP可以很自然地與許多現有的黑盒遷移攻擊方法相結合,以進一步提高方法的遷移性。在攻擊現實世界的圖像識別系統Google Cloud Vision API的實際實驗中,與其他基線方法相比,我們獲得了22%的有目標攻擊性能的提升。
?
12.?Effective Backdoor Defense by Exploiting Sensitivity of Poisoned Samples
作者:
Weixin Chen,?Baoyuan Wu, Haoqian Wang
簡介:
基于投毒的后門攻擊對于在來源不可信的數據上訓練深度模型構成了巨大的威脅。在后門模型中,我們觀察到帶有觸發器的毒性樣本的特征表示比干凈樣本的特征表示對圖像變換更敏感。它啟發我們設計了一個簡單的敏感性指標,稱為特征關于圖像變換的一致性 (FCT),用以區分不可信訓練集中的毒性樣本和干凈樣本。此外,我們提出了兩種有效的后門防御方法。基于一個利用FCT指標來區分樣本的模塊,第一種方法使用一個兩階段的安全訓練模塊從頭訓練出一個干凈模型。第二種方法使用后門移除模塊從后門模型中移除后門,該模塊交替地遺忘被區分的毒性樣本以及重新學習被區分的干凈樣本。在三個基準數據集上的大量實驗結果證明與當前的SOTA后門防御方法相比,我們的方法在8種類型的后門攻擊上都體現了優越的防御性能。
?
13.?BackdoorBench: A Comprehensive Benchmark of Backdoor Learning
*Accepted by NeurIPS 2022 Datasets and Benchmarks Track
作者:
Baoyuan Wu, Hongrui Chen, Mingda Zhang, Zihao Zhu, Shaokui Wei, Danni Yuan, Chao Shen
簡介:
后門學習是研究深度神經網絡(DNNs)脆弱性的一個新興的重要課題。許多開創性的后門攻擊和防御方法被陸續或同時提出,處于快速發展和競賽的狀態。然而我們發現,現有對新方法的評估往往是不徹底的,無法驗證其主張和實際性能,而這一點主要是由于快速發展、不同的環境以及實施和可重復性的困難。如果沒有徹底的評估和比較,就很難跟蹤當前的進展情況和規劃未來的發展方向。
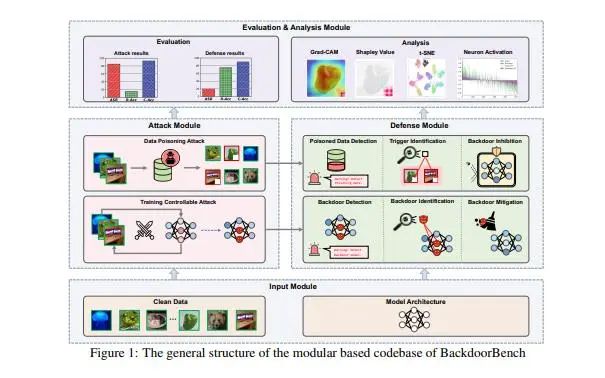
為了緩解這一困境,我們建立了一個全面的后門學習基準,并稱之為BackdoorBench。它由一個可擴展的、模塊化的代碼庫(目前包括8個最先進的(SOTA)后門攻擊和9個SOTA后門防御算法的實現),以及一個完整的后門學習的標準化協議組成。我們還提供了基于5個模型、4個數據集、8種攻擊、9種防御、5種中毒率的綜合評估,共計8000對的評估結果。我們還從不同角度對這8,000個實驗結果進行分析,研究攻擊對防御算法、中毒率、模型和數據集在后門學習中的影響。
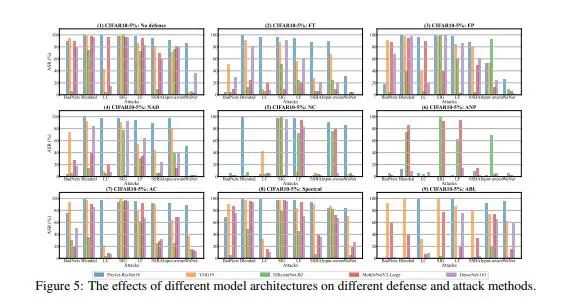
ackdoorBench的所有代碼和評估請移步https://backdoorbench.github.io。
?
14.?Distributionally robust weighted k-nearest neighbors
作者:
Shixiang Zhu,?Liyan Xie, Minghe Zhang, Rui Gao, Yao Xie
簡介:
本工作針對如何從有限樣本中學習一個魯棒的分類器,提出了一種基于k近鄰 (k-NN)的魯棒算法Dr. k-NN (Distributionally robust k-NN)。

在本工作中,我們研究了加權 k-NN 的極小化極大魯棒最優解,旨在找到對抗數據分布不確定性的最優加權 k-NN 分類器。本工作求解出了基于Wasserstein距離的數據驅動式魯棒最優加權 k-NN,它可以根據訓練樣本通過線性規劃的方式被高效計算,并在執行分類任務時為樣本分配最優權重。與傳統加權 k-NN的顯著區別是,Dr. k-NN為樣本賦予的權重會與類別相關,且由最不利場景下樣本特征的相似性決定。同時本工作證明了所提出的Dr. k-NN框架在理論上等效于 Lipschitz 范數正則化問題,從而進一步給出了泛化能力的理論刻畫。

本工作還將Dr. k-NN與基于神經網絡的特征嵌入相結合,提供了一種端到端的訓練方法。最后,本工作在各類真實數據實驗上證明了Dr. k-NN的良好性能。
鏈接:
https://arxiv.org/abs/2006.04004
?
15.?FedRolex: Model-Heterogeneous Federated Learning with Rolling Submodel Extraction
作者:
Samiul Alam, Luyang Liu,?Ming Yan, Mi Zhang
簡介:
聯邦學習 (FL) 是一種從分散的個人數據中訓練全局機器學習模型的協作模式。大多數 FL 研究側重于同質模型,它要求所有參與的客戶端和服務器上更新的模型是相同的。然而,在現實世界中,該約束限制了FL在客戶端存在異質模型情況下的應用,不公平地排除了具有低端設備的用戶的參與,使其不能從中受益。在這項工作中,我們提出了一種名叫FedRolex的簡單而有效的模型異構 FL 方法來解決這個約束。與模型同質場景不同的是,FL 中模型異質的根本挑戰是全局模型的不同參數在異構數據上訓練的不平衡。FedRolex 通過在每次迭代中滾動子模型來解決這一挑戰,以便全局模型的參數在所有設備的全部數據分布上得到均勻的訓練,使其更類似于模型同質訓練。實驗表明,FedRolex 優于其他模型異構 FL 方法,尤其是在數據異構顯著情況下。子模型滾動可以有效的減少模型異質和模型同質之間的差距。最后,我們考慮一種類似于現實世界收入分配的非均勻客戶端能力分布。實驗結果表明,低端設備的準確性得到了顯著的提高,增強了 FL 的包容性。
鏈接:
https://openreview.net/forum?id=OtxyysUdBE
*需注冊查看
?
16.?Communication-Efficient Topologies for Decentralized Learning with O(1) Consensus Rate
作者:
Zhuoqing Song, Weijian Li, Kexin Jin, Lei Shi,?Ming Yan, Wotao Yin, Kun Yuan
簡介:
無中心優化是一種新興分布式學習方法,它通過節點之間的點點通信替代中央服務器來訓練機器學習模型。由于通信往往比計算慢,當每個節點一次迭代只與幾個相鄰節點通信時,它們可以比使用更多節點或中央服務器更快地完成迭代。然而,無中心優化的總迭代次數受節點之間信息共識率的影響。我們發現現行的通信拓撲要么具有大度數(如星形圖和完整圖,這些拓撲的信息共識效率高,通信效率低),要么信息共識低效(如環和網格通行效率高)。為了解決這個問題,我們提出了一個新的拓撲類EquiTopo,它具有(幾乎)恒定的度數和與網絡大小無關的共識率。
鏈接:
https://openreview.net/forum?id=AyiiHcRzTd
*需注冊查看
?
17.?AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
作者:
Yuanfeng Ji, Haotian Bai, Jie Yang, Chongjian GE, Ye Zhu,?Ruimao Zhang, Zhen Li, Lingyan Zhang, Wanling Ma, Xiang Wan, Ping Luo
論文簡介:
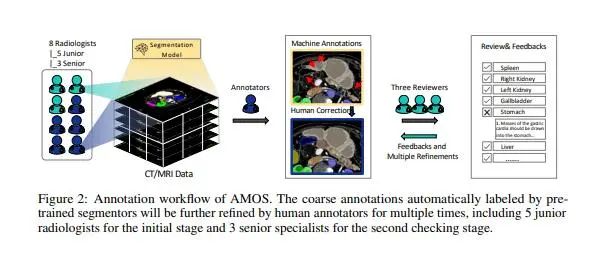
近年來,隨著深度學習技術的發展,基于醫學影像的腹部多器官語義分割取得了相當大的進展。但由于缺乏來自臨床應用的大規模測試基準,研究人員很難對各類模型進行公平全面的性能評估。同時,由于醫學內容分析所需要的專業知識較多,因此對應CT/MRI影像的標注成本也及其昂貴。精標注數據的匱乏,也進一步限制了面向醫學影像分析的深度模型的發展。為了解決上述問題,項目組聯合香港大學和深圳市大數據研究院共同提出了AMOS,一個大規模的、多樣化的、用于腹部器官語義分割的臨床數據集。
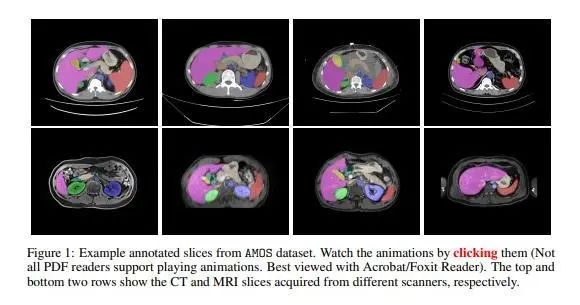
AMOS提供了500組CT和100組MRI掃描影像,收集自多中心、多廠商、多模式、多階段、多疾病的患者,每組掃描都包含有15個腹部器官的體素級精標注。該數據集的構建為研究不同目標和場景下的穩健分割算法提供了挑戰性的示例,以及統一公平的測試平臺。項目組現已公開了該數據集、以及不同的經典深度神經網絡模型在該數據集上的評測結果。希望該數據集的發布能夠對未來的模型研究工作帶來積極地推動作用。
鏈接:
https://arxiv.org/abs/2206.08023v1
?
18.?Adam Can Converge Without Any Modi?cation on Update Rules
作者:
Yushun Zhang, Congliang Chen, Naichen Shi,?Ruoyu Sun,?Zhi-Quan Luo
簡介:
Adam是深度學習中最廣泛使用的算法之一,但它的收斂性一直是個有爭議的話題。Reddi et al曾指出Adam會在簡單的凸問題上發散,給廣大工程師敲響了警鐘。自從那以后,很多工作嘗試通過修改Adam算法的機制來重新獲得收斂性保障。但于此同時,現實的深度學習任務中,未經任何修改的Adam仍然廣泛被工程師使用,且經常取得得非常好的表現。為什么理論上的發散在實踐中沒有被觀察到?我們指出Reddi et al. 的發散理論和實際場景存在差距:Reddi et al. 先固定Adam的超參數,后挑選優化問題;而實際任務往往是先給定優化問題,再調整Adam的超參數。?由于Adam通常在后一種情況下表現得很好,我們推測它仍然可以收斂。
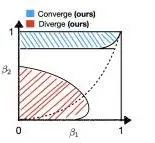
在本文中,我們在固定優化問題的場景下證實了這個猜想。我們證明,當二階動量參數 $\beta_2$ 很大且一階動量參數 $\beta_1 < \sqrt{\beta_2}<1$ 時,Adam 可以收斂。據我們所知,我們是第一個證明具有任意大 $\beta_1$ 的 Adam 可以在沒有任何形式的有界梯度假設的情況下收斂。這個結果表明,沒有任何修改的Adam在理論上仍然可以收斂。當$\beta_2$ 較小時,我們進一步指出Adam 可以發散到無窮。我們的發散結果考慮了與收斂結果相同的設定(提前固定優化問題),這表明當增加 $\beta_2$ 時存在從發散到收斂的相變。這些結果可能會為更好地調整 Adam 的超參數提供指導。
鏈接:
https://arxiv.org/abs/2208.09632v2
?
博士后郭丹丹、博士生張雨舜資料

郭丹丹
郭丹丹為我校數據科學學院博士后,師從查宏遠教授。郭丹丹2020年博士畢業于西安電子科技大學,此后在香港中文大學(深圳)機器人與智能制造研究院(IRIM)、數據科學學院進行博士后研究,她的主要研究方向是模式識別機器學習,包括概率模型構建與統計推斷,元學習,算法公平性研究以及最優傳輸理論。所涉及的應用有圖像生成及分類、文本分析、自然語言生成等。目前,她專注于現實應用中小樣本分類、小樣本生成、訓練數據分布有偏等問題,著重從分布校正、分布擬合、分布匹配等角度展開研究。她的科研成果發表在機器學習國際頂級會議、期刊上,如NeurIPS、ICML、ICLR、IJCV、TNNLS等。她也是多個國際會議的程序委員會委員和期刊審稿人,如ICML、NeurIPS、ICLR、JMLR、 TSP等。
?

張雨舜
張雨舜是我校數據科學學院四年級博士生,導師為羅智泉教授。張同學本科畢業于南方科技大學數學系,曾獲得南方科技大學優秀畢業生和數學系杰出十佳學生獎學金,研究方向是深度學習和優化理論。




